




Human beings stand out on the back of many different things, but nothing does the job quite like our tendency to improve at a consistent clip. This commitment towards getting better, no matter the situation, …
0
Human beings stand out on the back of many different things, but nothing does the job quite like our tendency to improve at a consistent clip. This commitment towards getting better, no matter the situation, has already brought the world some huge milestones, with technology emerging as quite a major member of the stated group. The reason why we hold technology in such a high regard is, by and large, predicated upon its skill-set, which guided us towards a reality that nobody could have ever imagined otherwise. Nevertheless, if we look beyond the surface for one hot second, it will become abundantly clear how the whole runner was also very much inspired from the way we applied those skills across a real world environment. The latter component, in fact, did a lot to give the creation a spectrum-wide presence, and as a result, initiated a full-blown tech revolution. Of course, the next thing this revolution did was to scale up the human experience through some outright unique avenues, but even after achieving a feat so notable, technology will somehow continue to bring forth the right goods. The same has turned more and more evident in recent times, and assuming one new discovery ends up with desired impact, it will only put that trend on a higher pedestal moving forward.
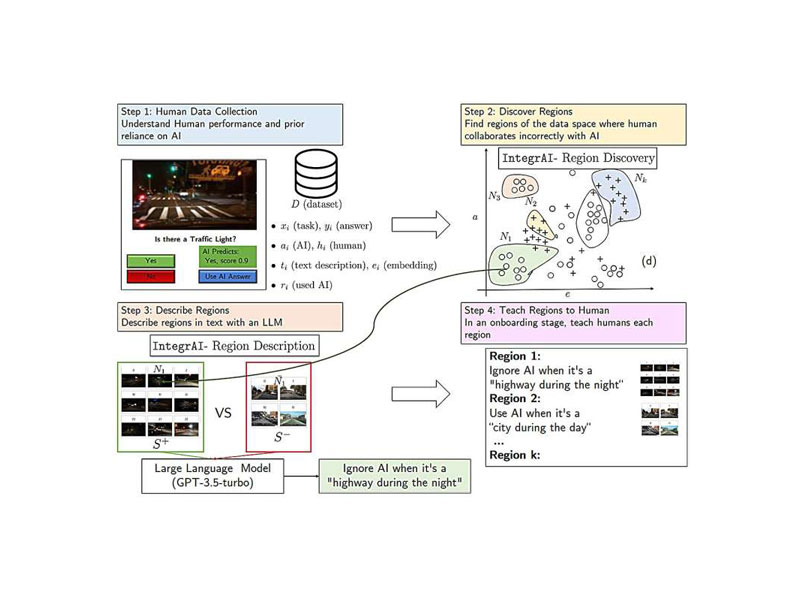
The researching teams at Massachusetts Institute of Technology and MIT-IBM Watson AI Lab have successfully developed an onboarding process which helps you figure out when to collaborate with an AI assistant. To understand the significance of such a development, though, we must start by acknowledging how most of the current onboarding methods covering human-AI collaboration are made from training materials that were conceived by human experts for specific use cases. Such a factor, like you can guess, makes them extremely difficult to scale. Now, while there are also other techniques that bet on proper explanations to make AI inform user on its confidence in each decision, but from what we have seen thus far, these explanations are rarely helpful. So, how will the new onboarding process solve such a conundrum? Well, the answer to that resides in its data-driven education. You see, the process comes decked up with a dataset which contains many instances of a task, such as detecting the presence of a traffic light from a blurry image. Talk about the way it will use that dataset in practice, it will start with collecting data on the human and AI performing a given task. Once the data is in through the door, the system integrates it into a latent space, which is a representation bringing data points relatively closer. Next up, it leverages a specialized algorithm to discover regions of this space where the human collaborates incorrectly with AI. Moving on, following the discovery, we have a second algorithm using a large language model to describe each region as a rule. Further fine-tuning that rule is the second algorithm’s tendency to find contrasting examples. Anyway, these rules are eventually put in place to build comprehensive training exercises. During the exercises, MIT’s latest brainchild shows the user an example, in the context of our earlier analogy: a blurry highway scene at night. Interestingly enough, it also shows AI’s prediction regarding the same, and keeping all that in mind, the system asks you to share your view over whether the image is able to show traffic lights. You can either make your own guess, or you can also use AI’s prediction. Now, if you happen to be wrong, you’ll be provided with the right answer, alongside performance statistics for the human and AI on these instances of the task. It will do so for each and every region, following it up by another shot at those exercises that the human got wrong.
“So often, people are given these AI tools to use without any training to help them figure out when it is going to be helpful. That’s not what we do with nearly every other tool that people use—there is almost always some kind of tutorial that comes with it. But for AI, this seems to be missing. We are trying to tackle this problem from a methodological and behavioral perspective,” said Hussein Mozannar, a graduate student in the Social and Engineering Systems doctoral program within the Institute for Data, Systems, and Society (IDSS) and lead author of a paper explaining this training process.
The researchers involved here have already tested their system on two different tasks i.e. detecting traffic lights in blurry images and answering multiple choice questions from many domains (such as biology, philosophy, computer science, etc.). Going by the available details, they first showed users a card with information about the AI model, how it was trained, and a breakdown of its performance on broad categories. An important bit of information, however, is that the stated card wasn’t shown to everyone in a similar manner. Having divided the subjects into separate groups, the researchers showed full information to only a few users. As for others, a chunk of them were filled in on just about the researchers’ onboarding procedure. Another group was given a lowdown on a baseline onboarding procedure, whereas some skimmed through the researchers’ onboarding procedure and were also given recommendations of when they should or should not trust the AI. There was another faction who was provided with nothing more than recommendations alone. The results displayed that the researchers’ onboarding procedure without recommendations improved users’ accuracy significantly, boosting their performance on the traffic light prediction task by about 5 percent, and doing that without slowing them down at any given point. On the other hand, the group that was delivered recommendations without onboarding not only performed worse, it also took more time to make predictions in the first place.
“When you only give someone recommendations, it seems like they get confused and don’t know what to do. It derails their process. People also don’t like being told what to do, so that is a factor as well,” said Mozannar.
For the group informed on just onboarding information, a lack of enough data turned out as the biggest challenge, rendering the operation ineffective.
With these findings in the books, the researchers’ plan for the future includes conducting larger studies to evaluate the short- and long-term effects of onboarding. Apart from that, they also hope to use unlabeled data to facilitate onboarding, while simultaneously finding methods for reducing the number of regions and keep important examples intact at the same time.
“One could imagine, for example, that doctors making treatment decisions with the help of AI will first have to do training similar to what we propose. We may need to rethink everything from continuing medical education to the way clinical trials are designed,” said David Sontag, senior author of the paper, a professor of EECS, a member of the MIT-IBM Watson AI Lab and the MIT Jameel Clinic, and the leader of the Clinical Machine Learning Group of the Computer Science and Artificial Intelligence Laboratory (CSAIL).