



Abstract Specialty drugs account for just 2% of all medicines prescribed, yet they are on pace to comprise 50% of the drug spend in the next few years – ballooning to $400B in the US …

0
Abstract
Specialty drugs account for just 2% of all medicines prescribed, yet they are on pace to comprise 50% of the drug spend in the next few years – ballooning to $400B in the US alone by 2020. Traditional approaches to drug utilization and cost management are simply not working. And biopharmaceutical pipelines are filled with new, high-priced, specialty drugs that continue to pressure health care budgets around the world.
There is currently estimated to be up to $20billion in annual, solvable Specialty Rx inefficiencies in the US alone. By identifying which drugs are most effective for which patients (precision analytics for precision medicine) can a Decision support system (DSS) help solve the growing problem with Specialty Drug Use and Cost out of Control? This trend is unsustainable to the healthcare system.
Can a Decision support system help payers and physicians make better (more optimized) specialty drug prescription decisions? By using DSS, can we help patients get the right drug, at the right time, at the right dose, with the right outcome? The target population for this study is Biopharma, payers, providers and patients and at-risk ACO that make evidence backed, value-based prescribing decisions. The paper will examine how DSS can support and help in building a more collaborative healthcare system among Biopharma, payers, provider and patients.
Introduction
Prices of specialty drugs are out of control, spending rising much faster than all other healthcare areas. Many patients are cheering for a change that can drive a fair cost to quality outcome ratio with strong emphases on value. Paying for value model is focusing on factors that embrace risk-based performance by healthcare organizations. At a macro level, the paper will examine if a decision support technology can enable such transformation will attempt to “bend the trend line” in both use and cost of specialty drugs.
Currently the growth in specialty trend is 15-20% per year, with no end in sight. A Strong emphasis of such a DSS is between payers and physicians make optimized specialty drug prescription decisions. Can a DSS help payers and at-risk providers make evidence backed, value-based prescribing decisions. This paper will attempt to demonstrate that DSS should help patients get the right drug, at the right time, at the right dose, with the right outcome, all while making a value-based (get the most benefit for least cost) decision. This decision, if optimized, can cut out significant waste and inefficiency out of specialty drug trend and spend.
Literature Review
This section describes the specific set of technologies; expert systems, machine learning that can help optimize the use of a decision support system and are ones that this paper aims to show relevant in guiding clinicians with selecting the optimal drug or treatment for a patient.
Expert Systems
An expert system is defined as a software solution that aims to reasons with knowledge of a specific subject with a view to solving problems or providing guidance. It usually consists of a Dataknowledge source and a mechanism for problem-solving that returns a response based on the information provided by inquiry. The knowledge source of most expert systems is based on direct input from domain experts and evidence from the literature. The process of transforming human knowledge to machine-usable form is called knowledge acquisition and is considered a bottleneck because it is time- and labor-intensive. In addition, maintaining the knowledge base is very labor-intensive.
Other systems use techniques such as case-based reasoning and machine-learning methods for inference and are thus based exclusively on data. They can avoid the knowledge acquisition problem, e.g., case-based reasoning, the knowledge consists of previous cases, including the problem, the solution, and the outcome, stored in a central location. To obtain the solution for a new case, one simply identifies the case that is most similar to the problem, and the proposed solution can be adapted from the retrieved information.
Machine Learning
Machine learning is an area of artificial intelligence that uses algorithms to, for example, improve performance over time, or find patterns in data. Generally, machine learning methods can be classified as supervised and unsupervised methods. Supervised methods are trained with labeled data; that is, cases that have known outcomes. Decision functions, which result from the training process, can transfer variable values into predicted scores or labels. This paper will review prediction performance by comparing with true labels, which is a process called validation. In order to implement this idea, one needs to divide a dataset into two subsets, one for training and the other one for testing or comparing. A better validation method with low variance, low bias, and easy computation properties is called n-fold cross-validation, which uses n − 1 partitions of the data for training and one fold for testing and repeats the process for n times. Unsupervised methods learn from unlabeled data, and group data based on similarity.
The decision functions of supervised learning methods constitute the knowledge that is mined from data. With an appropriate design, this can be applicable to many problems, for example, clinical outcome prediction, drug prescription recommendation, etc.
Combining Expert System and Machining Learning
Combining machine learning in expert systems is achievable in a limited use. Most methods that can provide help rule orientation methods. These methods are limited to originating rules, evaluating rules, and optimizing the performance of rules for expert systems.
However, with an appropriate design, one can directly turn machine learning algorithms into expert systems. Machine learning approaches are renowned for knowledge discovery. They can model real world problems using decision functions that exist in the form of mathematical equations, rules, or decision trees.
These methods can predict well and provide useful information. Using a mathematical form of knowledge has the advantages of stability, observability, and controllability. However, capturing a complex real-world model using a mathematical equation is difficult. These capabilities make Expert systems and Machine learning prime candidates to help improve decision-making healthcare.
Decision Support Systems in Health Care
The idea of decision support has been widely acknowledged in health care, starting from a simple database query to complex treatment recommendation. The development of clinical decision support systems (CDSSs) has drawn much attention. The knowledge of CDSSs exists in the form of guidelines. There are four areas in the process of developing a guideline-based decision support system: 1. Guideline modeling and representation. This area focuses on the representation of a guideline, e.g., the form of expression, knowledge type, maintenance, etc. 2. The area is guideline acquisition, which is a process that facilitates the knowledge attainment process directly from a domain expert 3. The area is guideline verification and testing. This process aims to ensure the machine-interpretable guideline is clear-cut and syntactically as well as semantically correct 4. Guideline execution, which focuses on the execution time and ensures the guideline engine can run in multiple clinical domains and in various modes.
An alternative approach to guideline-based approach is machine learning, e.g., artificial neural networks or support vector machines, provides a systematic review of these approaches that provides decision support in cancer. Instead of the required process from guideline modeling to execution, these approaches gain knowledge automatically from clinical data and then use the knowledge to provide decision support.
CDSSs provide several functions to assist medical decisions. Medication-related CDSS can provide basic and advanced decision support. Basic decision support includes drug-allergy checking, basic dosing guidance, formulary decision support, duplicate therapy checking, and drug-drug interaction checking. The advanced decision supports includes dosing support for renal insufficiency and geriatric patients, guidance for medication-related laboratory testing, drug-pregnancy checking, and drug disease contraindication checking. Thus, CDSSs can help to reduce medication error rate, prescribing behaviors, corollary orders, etc.
CDSSs seem very helpful in supporting medical decisions, but it is difficult to get health providers to actually use them, the following rules have been summarizing by industry experts for successful implementation of CDSSs. These rules are: 1. speed of providing the recommendation; 2. anticipate needs and deliver in real time 3. fit into the user’s workflow 4. Little things can make a big difference (usability matters) 5. Recognize that physicians will strongly resist stopping 6. Changing direction is easier than stopping 7. Simple interventions work best (fit a guideline on a single screen); 8. Ask for additional information only when you really need it 9. Monitor impact, get feedback and respond 10. Manage and maintain your knowledge-based systems.
Drivers for Change – Pain Points
Among all the players involved: Biopharma, Payers, Providers and Patients, Payers are impacted the most today (along with government and employers) because they carry the insured risk and must “pay the bills” which are currently out of control when it comes to specialty drugs. They would be a great target for a decision support tool that can help with a more optimized decision support, however, provider groups (e.g. Health systems or ACOs) who will eventually be moving from fee-for-service to pay for performance models will be sharing the risk with payers, and they will become a potential for a role of a primary user.
A decision support system or platform can work if there is a full buy-in of physicians and if it is integrating with their current EMR or ePrescribing platform, and allow them to be guided with a decision at the point of care (at the moment they want to make a prescribing decision for specialty drugs), this practice is invaluable to caregivers, in making a great decision on behalf of their patients. For this to take place we will need an intelligence layers and predictive analytics that will help them make the very best choice for each unique patient – a decision that is backed by the evidence and is value based.
Pharmaceutical companies will eventually consider a DSS when realizing that they too will eventually need to move to pay for performance, and will start doing risk-based contracts. Thus, in the future, Pharmaceutical will likely only get paid for the use of their product when it is appropriate to use (for the right patient type as identified by a diagnostic test or a biomarker) and when it works (when patient gets the outcome expected) and/or when the patients successfully stays on the product as prescribed (adherence to the drug even though there may be some side effects).
Finally, while the patient is the ultimate customer, the decisions made by a provider that use DSS can ultimately benefit the patient – both because they got the best outcome for the drugs they took, and because we optimized for value (thus helping the patient get the best drug for them at the best price). Since patient cost sharing continues to rise for these expensive specialty drugs, they will want to know they are getting the right treatment at the best value.
Take Hepatitis C as an example; there are currently 3 branded competitors in the Hepatitis C space. These new drugs not only manage symptoms, but they actually cure the disease 95% of the time. With that said, a 12-week regimen costs $84,000. Many of the patients are newly diagnosed because they are being pushed by the biopharma advertisements to get tested for Hepatitis C if they have ever in their life gotten a blood transfusion or used needles for anything (think baby boomers experimenting with drug use back in the ‘60s and ‘70s!).
Many have no disease symptoms, but once tested are demanding these high priced drugs. On the other end of the spectrum, if you have severe Hepatitis C, you could require a liver transplant that costs $300K and annual maintenance costs of $40K/year for life after the transplant. Sounds like a no-brainer, to give everyone the new cure-all drugs, right? Not exactly. Most folks don’t ever have symptoms and most never will progress to needing a transplant. Thus, there’s an evidence backed, the value-based decision that needs to be made for each patient were decision support system is well positioned.
Benefits, opportunities, costs and risks to potential customers
For a decision support system to be effective in this scenario we must have access to EMR and Claims data both; at the start you can utilize machine learning regression tests to conduct a retrospectively at all Hepatitis C patients. We would then look at treatment patterns and the associated outcomes and costs. Collecting and analyzing evidence created by machine learning algorithms will suggest optimal specialty drug treatment for the same patients as we analyzed in the control group.
We would then determine which patients would have made a different prescribing decision versus the one actually made by the doctor. Essentially our goal would be to show both the health plan and the health system where they could have made more optimal/efficient specialty drug decisions to get the same or better outcomes at lower total cost. This would be demonstrating that we can find these inefficiencies in either inappropriate use or non-optimal cost or both.
Ultimately the goal of a decision support tool would be to de-risk decision-making process for providers, or impacting Utilization Management guidelines in the health plan, or optimize their formulary for better pricing.
Optimal Decision Support Tool
On the payer side, providing a product for their leadership team in Utilization Management (UM) and Formulary Management. On the UM side, we want to surface actionable insights via analytics that show where they are leaking value in their current UM workflows, policies guidelines. For example, we might suggest changes to their prior authorization policy for drug A, or we might suggest that for sub-population B they evidence shows the plan could lower cost by using step therapy (trying and failing on drug A, before being allowed to try more expensive drug B).
Imagine “cockpit” type visual set of metrics displayed, with the opportunity to drill downs into the data, and/or produce a variety of performance reports that point out where they health plan could remove inefficiencies and waste in the specialty Rx decision through changes to existing UM processes. The same type approach could be taken on the Formulary Management side as well. But instead of focusing on appropriate and inappropriate use, we would instead provide the plan with actionable insights and evidence to suggest where they could negotiate a better deal with specific biopharma manufacturers (especially for under-performing drugs).
On the physician side, a compelling user interface should be the goal. This user interface will attempt to tap into the existing evidence base – both published studies as well as Real World Evidence (RWE) from the data we have collected/combined/analyzed. We would scrape and display existing descriptive analytics for the specific patient the provider wants to prescribe a Rx from the EMR we are sitting on, so as to minimize their need to re-enter descriptive info (e.g., patient age, gender, co-morbidities, current meds, etc.).
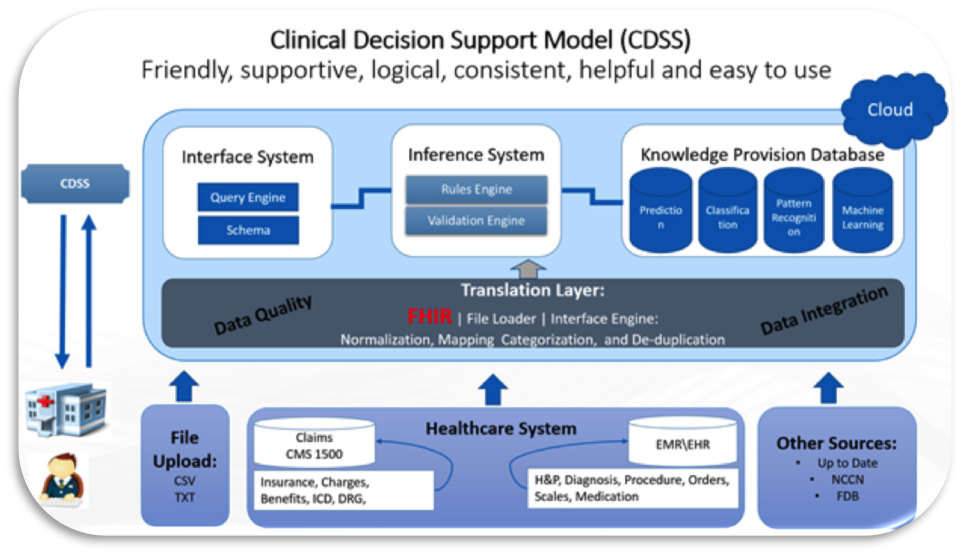 We would have a section where the provider can review the published evidence but also we would give them a Meta summary of the evidence. We would create and display a dashboard of summary scores for the comparable Rx products. These scores would be generated by running machine learning and predictive algorithms that bounce a unique patient’s information up against a population model to determine first, what sub-population to include this individual in, and then to generate a number of comparisons “scores” for the physician to consider in making the decision. For example, if we had drug A, B and C as our three choices, you might choose to display a sub-score for each drug, for several categories, such as drug efficacy, drug adherence, drug cost, etc. There then might be an overall recommendation for which drug to try first, second, and third. The figure below illustrates a possible flow of information from the time originated and its transformation to a provider as a decision support tool.
We would have a section where the provider can review the published evidence but also we would give them a Meta summary of the evidence. We would create and display a dashboard of summary scores for the comparable Rx products. These scores would be generated by running machine learning and predictive algorithms that bounce a unique patient’s information up against a population model to determine first, what sub-population to include this individual in, and then to generate a number of comparisons “scores” for the physician to consider in making the decision. For example, if we had drug A, B and C as our three choices, you might choose to display a sub-score for each drug, for several categories, such as drug efficacy, drug adherence, drug cost, etc. There then might be an overall recommendation for which drug to try first, second, and third. The figure below illustrates a possible flow of information from the time originated and its transformation to a provider as a decision support tool.
Decision Support System & Precise Analytic Methods
There are a series of stages in the Prediction and Optimization-Based Decision Support System algorithm this paper see a good fit for drug decision support. As illustrated in the Figure below, the algorithm relies on classifiers to capture knowledge about clinical and non-clinical (claims) data on patients utilized for training a prediction model, Independent, and dependent variables are required to train the model. The output score of the prediction model, which we convert to a probability, can be interpreted as the confidence level of the desired action by the clinician. The purpose of optimization is to maximize the confidence level of the desired action by selecting the best drug or treatment that is evidence based and most valuable to the patient.
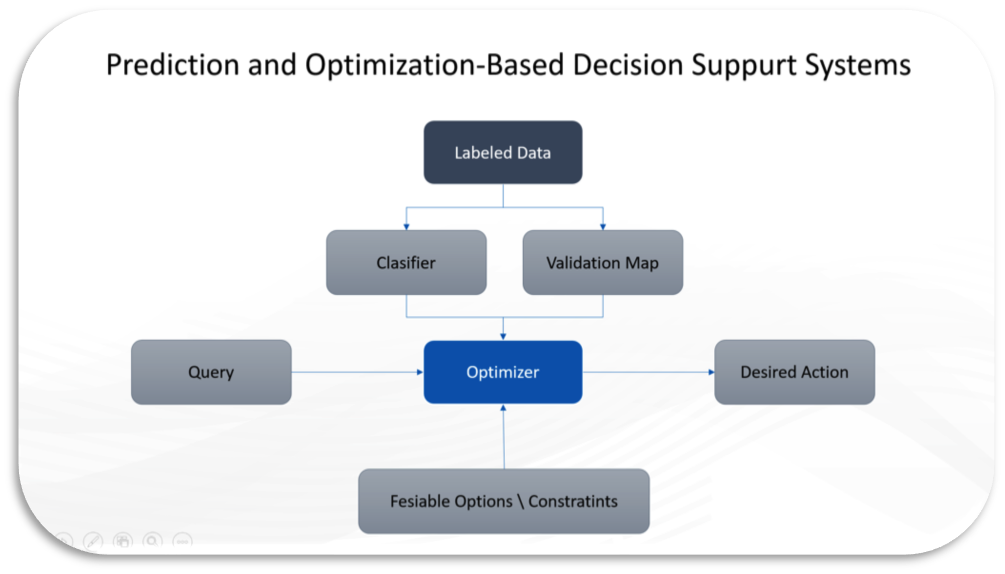 This expert system is constructed by the Prediction and Optimization-Based Decision Support System algorithm, the algorithm consists of three major parts: the prediction model, the optimizer, and the validation map. As most prediction problems, a classifier is trained with clinically and non-clinical labeled data. The labels are assumed to be the complete patient care cycle as we know it from the systems used to capture the information (e.g., EMRFinance systems). The predicted scores can be seen as confidence. When we change the values of a subset of variables, the confidence will be different. Thus, we can use an optimizer to optimize the confidence of the desired label and decide what actions clinician should take. You can see how this can be a relevant method in healthcare right?
This expert system is constructed by the Prediction and Optimization-Based Decision Support System algorithm, the algorithm consists of three major parts: the prediction model, the optimizer, and the validation map. As most prediction problems, a classifier is trained with clinically and non-clinical labeled data. The labels are assumed to be the complete patient care cycle as we know it from the systems used to capture the information (e.g., EMRFinance systems). The predicted scores can be seen as confidence. When we change the values of a subset of variables, the confidence will be different. Thus, we can use an optimizer to optimize the confidence of the desired label and decide what actions clinician should take. You can see how this can be a relevant method in healthcare right?
In many situations, we can consider probabilities over scores. A calibration method can transfer scores into probabilities. The calibration method can also provide indirect validation; therefore, it is called the validation map. Through this map, we can observe whether or not the change of actionable variables can influence the outcome.
Independent variables related to disease diagnosis, drug prescription or administration that can change and move a point are called controllable (changeable) variables, and variables that cannot change are called uncontrollable. In the optimization formulation, the controllable variables are the decision variables. When maximizing the decision function, a point can be moved toward the desired outcome maximally and the confidence of the desired outcome is maximum. Decision variables are the recommended action(s). The decision function is the knowledge source derived from the clinical and non-clinical data sources, and the optimization method is the mechanism for problem solving, which returns a customized recommendation based on the query’s individual information.
The optimization should provide a feasible recommendation to clinicians. If the way to generate answers is selection, we simply provide feasible choices of solutions, and the optimizer will select the best one. In the selection problem, we can use exhaustive search or heuristic search to find the solution. When the way to obtain the answer is construction, the optimizer needs to construct an answer. In this case, the mathematical programming can construct the answer. Without any constraint, the optimum recommendation may be infeasible in the real world. In order to solve this problem, the optimum answer should be subjected to certain constraints provided by human knowledge. Thus, expert knowledge can be incorporated into the optimization process.
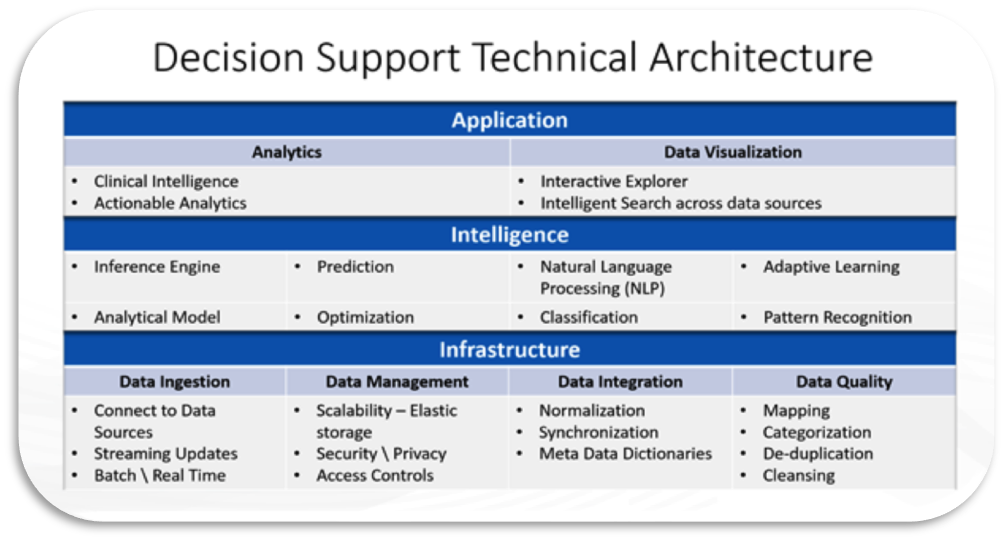
The figure below illustrates the technical architecture in a form of building blocks needed to utilize for successful implementation of decision support system.
 Conclusion
Conclusion
Decision support technology holds great promise to improve the quality of health care and reduce potential and real errors in medication management while at the same time providing cost-effective care. Using DSS in healthcare settings produced evidence summaries related to costs and benefits, barriers and drivers that have the potential to impact the way Biopharma, payers, providers and patients interact with the healthcare system. This paper is offering a narrow window to the possibilities and opportunities awaiting. The time for dabbling is over. A complex, fragmented, rapidly changing healthcare environment demands a strategic and comprehensive approach for targeting and engaging with patient care, we all must focus on where the ball is going to be, not where it has been. The opportunity for engaging Biopharma, payers, providers and patients with using Decision Support Technologies and creating patient-centric solutions that are transparent is now! It is in building the complete picture and targeting the small percentage of patients who will drive the biggest percentage of costs.
About the author
 Roni H. Amiel, CTO, Frost Data Capital – Pinscriptive
Roni H. Amiel, CTO, Frost Data Capital – Pinscriptive
Experienced Healthcare CIO, CISO & CTO with a unique blend of entrepreneurial and corporate background leveraging technology to demonstrate R&D, Clinical, Informatics, Businesses value and Competitive Momentum that thrives in very dynamic, high pressure, turnaround and crisis situations. Adaptable Manager with a powerful combination of in depth business acumen, technology knowledge, relationship and communication skills and the ability to optimize technology investments for the benefit of the organization.